Agent Skills Best Practices: Complete Guide to Writing Effective Claude Skills
Agent skills best practices for writing effective Claude Skills. Learn agent skills best practices from core principles like conciseness and progressive disclosure to advanced patterns with executable code.

This article is based on Anthropic's official documentation on Skill Authoring Best Practices.
Following agent skills best practices is essential for writing Claude Skills that work reliably. This guide covers the most important agent skills best practices — practical authoring decisions to help you write Claude Skills that Claude can discover and use effectively.
Core Agent Skills Best Practices
Concise Is Key
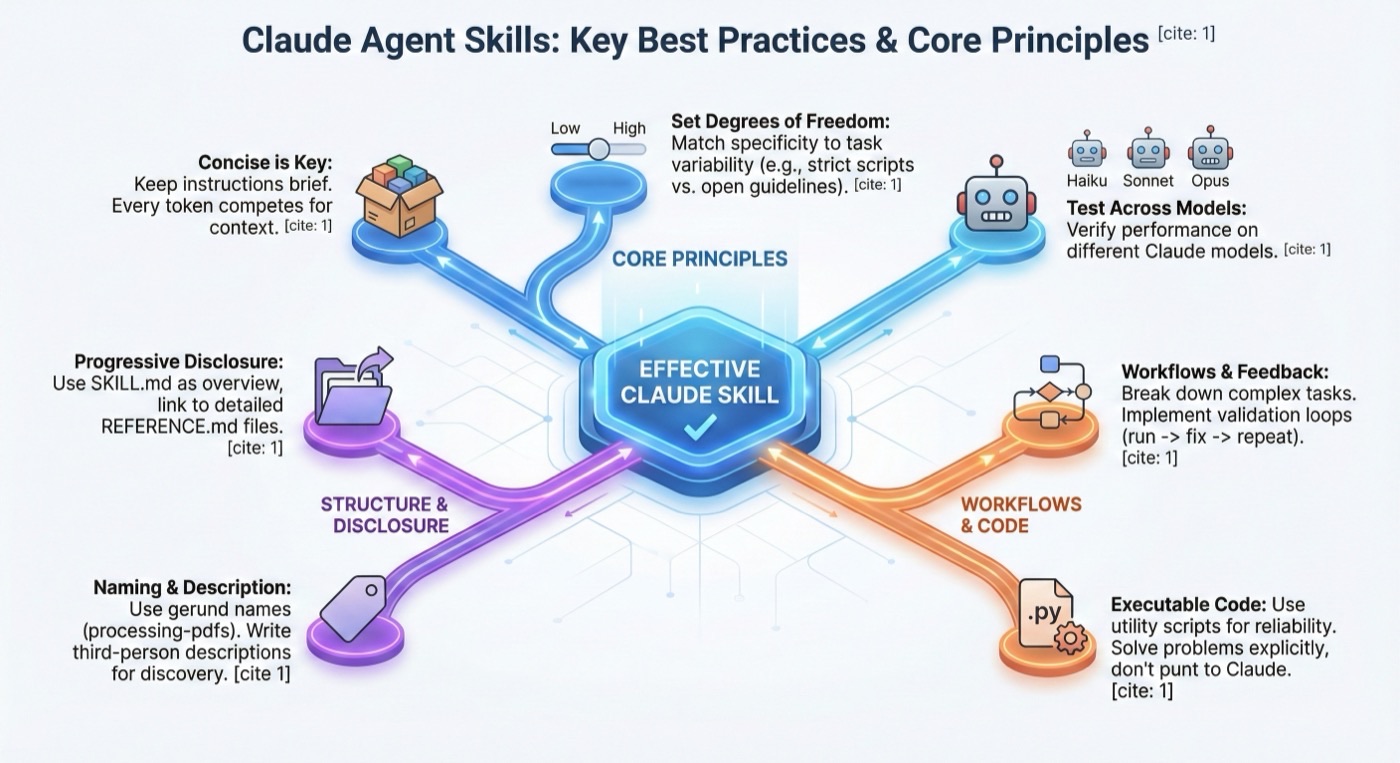
One of the most important agent skills best practices is conciseness. Your Skill shares the context window with everything else Claude needs to know, including the system prompt, conversation history, other Skills' metadata, and your actual request.
Not every token in your Skill has an immediate cost. At startup, only the metadata (name and description) from all Skills is pre-loaded. Claude reads SKILL.md only when the Skill becomes relevant. However, being concise in SKILL.md still matters: once Claude loads it, every token competes with conversation history and other context.
Default assumption: Claude is already very smart. Only add context Claude doesn't already have. Challenge each piece of information:
- "Does Claude really need this explanation?"
- "Can I assume Claude knows this?"
- "Does this paragraph justify its token cost?"
Good example (~50 tokens):
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
Bad example (~150 tokens):
## Extract PDF text
PDF (Portable Document Format) files are a common file format that contains
text, images, and other content. To extract text from a PDF, you'll need to
use a library. There are many libraries available for PDF processing, but we
recommend pdfplumber because it's easy to use and handles most cases well...
The concise version assumes Claude knows what PDFs are and how libraries work.
Set Appropriate Degrees of Freedom
Match the level of specificity to the task's fragility and variability.
High freedom (text-based instructions) — use when multiple approaches are valid:
## Code review process
1. Analyze the code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify adherence to project conventions
Medium freedom (pseudocode or scripts with parameters) — use when a preferred pattern exists:
## Generate report
Use this template and customize as needed:
```python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
```
Low freedom (specific scripts, few or no parameters) — use when operations are fragile:
## Database migration
Run exactly this script:
```bash
python scripts/migrate.py --verify --backup
```
Do not modify the command or add additional flags.
Think of Claude as a robot exploring a path:
- Narrow bridge with cliffs: There's only one safe way forward. Provide exact instructions (low freedom).
- Open field: Many paths lead to success. Give general direction (high freedom).
Test with All Models You Plan to Use
Skills act as additions to models, so effectiveness depends on the underlying model:
- Claude Haiku (fast, economical): Does the Skill provide enough guidance?
- Claude Sonnet (balanced): Is the Skill clear and efficient?
- Claude Opus (powerful reasoning): Does the Skill avoid over-explaining?
What works perfectly for Opus might need more detail for Haiku.
Agent Skills Best Practices for Skill Structure
Naming Conventions
Use gerund form (verb + -ing) for Skill names. The name field must use lowercase letters, numbers, and hyphens only.
Good examples:
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation
Avoid:
- Vague names:
helper,utils,tools - Overly generic:
documents,data,files - Reserved words:
anthropic-helper,claude-tools
Writing Effective Descriptions
The description field enables Skill discovery and should include both what the Skill does and when to use it.
Always write in third person. The description is injected into the system prompt:
- Good: "Processes Excel files and generates reports"
- Avoid: "I can help you process Excel files"
Effective examples:
# PDF Processing
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
# Excel Analysis
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.
# Git Commit Helper
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.
Progressive Disclosure Patterns
SKILL.md serves as an overview that points Claude to detailed materials as needed.
- Keep SKILL.md body under 500 lines for optimal performance
- Split content into separate files when approaching this limit
Pattern 1: High-Level Guide with References
---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents.
---
# PDF Processing
## Quick start
Extract text with pdfplumber:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## Advanced features
**Form filling**: See [FORMS.md](FORMS.md) for complete guide
**API reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patterns
Pattern 2: Domain-Specific Organization
bigquery-skill/
├── SKILL.md (overview and navigation)
└── reference/
├── finance.md (revenue, billing metrics)
├── sales.md (opportunities, pipeline)
├── product.md (API usage, features)
└── marketing.md (campaigns, attribution)
When a user asks about sales metrics, Claude only needs to read sales-related schemas, not finance or marketing data.
Pattern 3: Conditional Details
# DOCX Processing
## Creating documents
Use docx-js for new documents. See [DOCX-JS.md](DOCX-JS.md).
## Editing documents
For simple edits, modify the XML directly.
**For tracked changes**: See [REDLINING.md](REDLINING.md)
**For OOXML details**: See [OOXML.md](OOXML.md)
Avoid Deeply Nested References
Claude may partially read files when they're referenced from other referenced files. Keep references one level deep from SKILL.md.
Bad (too deep):
SKILL.md → advanced.md → details.md → actual information
Good (one level):
SKILL.md → advanced.md
SKILL.md → reference.md
SKILL.md → examples.md
Structure Longer Reference Files with TOC
For reference files longer than 100 lines, include a table of contents at the top:
# API Reference
## Contents
- Authentication and setup
- Core methods (create, read, update, delete)
- Advanced features (batch operations, webhooks)
- Error handling patterns
- Code examples
Agent Skills Best Practices for Workflows and Feedback Loops
Use Workflows for Complex Tasks
Break complex operations into clear, sequential steps with checklists:
## Research synthesis workflow
Copy this checklist and track your progress:
```
Research Progress:
- [ ] Step 1: Read all source documents
- [ ] Step 2: Identify key themes
- [ ] Step 3: Cross-reference claims
- [ ] Step 4: Create structured summary
- [ ] Step 5: Verify citations
```
**Step 1: Read all source documents**
Review each document in the `sources/` directory. Note the main arguments.
**Step 2: Identify key themes**
Look for patterns across sources. What themes appear repeatedly?
**Step 3: Cross-reference claims**
For each major claim, verify it appears in the source material.
**Step 4: Create structured summary**
Organize findings by theme with supporting evidence.
**Step 5: Verify citations**
Check that every claim references the correct source. If incomplete, return to Step 3.
Implement Feedback Loops
The common pattern: Run validator -> fix errors -> repeat
## Document editing process
1. Make your edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review the error message carefully
- Fix the issues in the XML
- Run validation again
4. **Only proceed when validation passes**
5. Rebuild: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
Content Guidelines
Avoid Time-Sensitive Information
Bad (will become wrong):
If you're doing this before August 2025, use the old API.
After August 2025, use the new API.
Good (use "old patterns" section):
## Current method
Use the v2 API endpoint: `api.example.com/v2/messages`
## Old patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
The v1 API used: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>
Use Consistent Terminology
Choose one term and use it throughout:
- Good: Always "API endpoint", always "field", always "extract"
- Bad: Mix "API endpoint" / "URL" / "API route" / "path"
Common Patterns
Template Pattern
## Report structure
ALWAYS use this exact template structure:
```markdown
# [Analysis Title]
## Executive summary
[One-paragraph overview of key findings]
## Key findings
- Finding 1 with supporting data
- Finding 2 with supporting data
## Recommendations
1. Specific actionable recommendation
2. Specific actionable recommendation
```
Examples Pattern
Provide input/output pairs just like in regular prompting:
## Commit message format
**Example 1:**
Input: Added user authentication with JWT tokens
Output:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**Example 2:**
Input: Fixed bug where dates displayed incorrectly in reports
Output:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
Conditional Workflow Pattern
## Document modification workflow
1. Determine the modification type:
**Creating new content?** -> Follow "Creation workflow" below
**Editing existing content?** -> Follow "Editing workflow" below
2. Creation workflow:
- Use docx-js library
- Build document from scratch
- Export to .docx format
3. Editing workflow:
- Unpack existing document
- Modify XML directly
- Validate after each change
- Repack when complete
Agent Skills Best Practices for Evaluation and Iteration
Build Evaluations First
Among the most critical agent skills best practices: create evaluations BEFORE writing extensive documentation. This ensures your Skill solves real problems.
Evaluation-driven development:
- Identify gaps: Run Claude on representative tasks without a Skill. Document specific failures
- Create evaluations: Build three scenarios that test these gaps
- Establish baseline: Measure Claude's performance without the Skill
- Write minimal instructions: Create just enough content to address the gaps
- Iterate: Execute evaluations, compare against baseline, and refine
Develop Skills Iteratively with Claude
Work with one instance of Claude ("Claude A") to create a Skill that will be used by other instances ("Claude B"):
- Complete a task without a Skill: Work through a problem with Claude A. Notice what information you repeatedly provide.
- Identify the reusable pattern: After completing the task, identify what context would be useful for similar future tasks.
- Ask Claude A to create a Skill: Claude models understand the Skill format natively.
- Review for conciseness: Check that Claude hasn't added unnecessary explanations.
- Test on similar tasks: Use the Skill with Claude B on related use cases.
- Iterate based on observation: If Claude B struggles, return to Claude A with specifics.
Advanced: Skills with Executable Code
Solve, Don't Punt
Handle error conditions rather than punting to Claude:
# Good: Handle errors explicitly
def process_file(path):
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
# Bad: Punt to Claude
def process_file(path):
return open(path).read()
Provide Utility Scripts
Pre-made scripts offer advantages over generated code:
- More reliable than generated code
- Save tokens (no need to include code in context)
- Save time (no code generation required)
- Ensure consistency across uses
Create Verifiable Intermediate Outputs
For complex tasks, use the "plan-validate-execute" pattern:
- Analyze -> create plan file -> validate plan -> execute -> verify
This catches errors early, provides machine-verifiable validation, and enables clear debugging.
Anti-Patterns to Avoid
- Windows-style paths: Always use forward slashes (
scripts/helper.py, notscripts\helper.py) - Too many options: Provide a default approach with an escape hatch, not a menu of choices
- Vague descriptions: "Helps with documents" tells Claude nothing useful
- Deeply nested references: Keep all references one level deep from SKILL.md
- Magic numbers: Document why configuration values are what they are
Agent Skills Best Practices Checklist
Core Quality
- Description is specific and includes key terms
- Description includes both what the Skill does and when to use it
- SKILL.md body is under 500 lines
- Additional details are in separate files (if needed)
- No time-sensitive information
- Consistent terminology throughout
- Examples are concrete, not abstract
- File references are one level deep
- Progressive disclosure used appropriately
- Workflows have clear steps
Code and Scripts
- Scripts solve problems rather than punt to Claude
- Error handling is explicit and helpful
- No magic constants (all values justified)
- Required packages listed and verified as available
- Validation/verification steps for critical operations
- Feedback loops included for quality-critical tasks
Testing
- At least three evaluations created
- Tested with Haiku, Sonnet, and Opus
- Tested with real usage scenarios
- Team feedback incorporated